
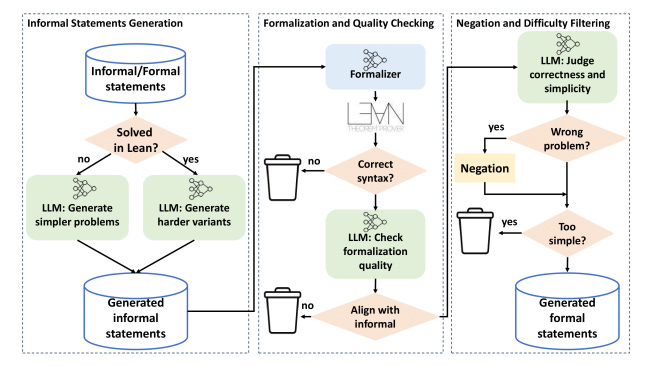
The Industrialization of Mathematics
2025 Year in Review for AI in Mathematics and Formal Methods.


2025 will likely be remembered not as another year of model scaling, but as the point at which artificial intelligence began to cross a more consequential boundary: from probabilistic inference toward formal verification.
The shift is subtle in appearance, but profound in implication. For the first time, large-scale AI systems started to treat correctness not as an emergent property, but as a hard constraint.
Poets, Compilers, and Conductors
For most of the past decade, progress in large language models rested on a single principle: statistical likelihood. Given enough text and enough parameters, a model could predict the next token with extraordinary accuracy. While this paradigm produced systems of remarkable fluency, it fundamentally failed to address the core requirement of mathematics, science, and high-assurance software: absolute correctness.
The Conductor
In The Shape of Math to Come, Alex V. Kontorovich argued that while 99 percent accuracy is miraculous in poetry, a single error in a thousand-step argument renders the entire construct meaningless.
To reconcile the bitter lesson of computation with the guided intuition of the mathematician, Kontorovich introduced the metaphor of the mathematician as Conductor. In this model the human provides a high-level blueprint or semantic map while specialized AI agents handle the granular logic. He deconstructed the monolithic AI mathematician into four roles: a Decomposer that breaks high-level ideas into manageable lemmas, a Translator that converts natural language intent into formal syntax, a Solver that uses search algorithms to close logical goals, and the human Conductor that orchestrates the workflow.
The Compiler
This theoretical shift was matched by a structural critique from researcher Zixi Li. In When Euler Meets Stack, Li argued that the energy dissipation paradigm of standard stability theory was insufficient for reasoning. Li proposed a Structural Stability Principle which proves that reasoning stability requires specific constraints such as discrete pointers and stack operators rather than just energy functions. This implies that true mathematical reasoning requires a discrete architecture rather than the continuous approximation methods of standard language models.
What consolidated in 2025 was the fusion of these insights into a revived paradigm: Neurosymbolic Reasoning. By combining the intuitive pattern-matching capabilities of large reasoning models with the rigorous logical constraints of interactive theorem provers like Lean 4, researchers birthed systems capable of Self-Verifiable Reasoning. The result is a qualitative shift in how mathematical knowledge is produced. Proof, long treated as an artisanal activity dependent on individual expertise, is becoming an industrial process. Statements are generated, checked, rejected, and refined under explicit logical constraints. Truth is no longer inferred. It is verified.
From an investment perspective, this marks the opening of an entirely different market. Capital is no longer flowing primarily into systems that sound correct but into systems that can guarantee correctness. A verified smart contract, a provably bounded model, or a formally validated chip design carries economic value precisely because it removes categories of risk that probabilistic systems cannot.
How Mathematical Reasoning Became Scalable
The breakthroughs in mathematical AI did not happen in a vacuum. They were powered by a fundamental shift in general LLM architecture defined by the transition from System 1 (Pattern Matching) to System 2 (Deliberative Reasoning).
I. The Engine Room: Inference-Time Scaling
The most commercially consequential development of 2025 was the shift from fast inference to slow reasoning. Intelligence began to be treated not as a fixed property of a model’s weights but as a variable controlled at inference time by how long the model is allowed to think. This reframing changed the locus of progress. Rather than asking only how to train better models, researchers began asking how to allocate computation during inference to maximize correctness.
The Foundation: Verifiable Rewards
Underpinning this shift was the consolidation of Reinforcement Learning with Verifiable Rewards (RLVR). In contrast to conventional RLHF, which relies on opaque human preferences, RLVR anchors learning in objective truth. Models are rewarded only when their output satisfies a compiler, theorem prover, or rule-based checker. This change incentivized correct reasoning rather than superficial pattern matching, creating a bridge to inference-time strategies: models trained to respect verification constraints became capable of deploying longer, self-correcting reasoning traces without collapsing into hallucination.
Algorithmic Efficiency: GRPO
This change at inference time was matched by a shift in training methodology. Traditional reinforcement learning approaches such as Proximal Policy Optimization relied on a separate critic model to evaluate intermediate steps, which introduced substantial computational overhead.
GRPO removes the critic entirely and replaces it with relative evaluation. Multiple candidate outputs are generated for the same prompt and ranked against a ground-truth verifier. The policy is optimized based on relative success rather than absolute value estimates. This approach preserves learning signal while dramatically reducing training cost, narrowing the gap between proprietary and open research and enabling smaller labs to train competitive reasoning models without access to large-scale private infrastructure.
Sparse Attention at Scale
Slow reasoning places heavy demands on context length, since intermediate steps must be stored and revisited. Standard attention mechanisms scale quadratically with sequence length, making extended reasoning traces prohibitively expensive.
This constraint was addressed at scale by DeepSeek with the release of DeepSeek-V3.2 in December 2025. The model introduced DeepSeek Sparse Attention, which replaces full attention with selective computation. DSA uses a Lightning Indexer to select only the top-k relevant tokens for computation, reducing costs to near-linear levels.
A high-compute configuration of this architecture, known as the Speciale variant, leveraged extended test-time computation to achieve gold medal level performance at the International Mathematical Olympiad and the International Olympiad in Informatics in 2025. This result demonstrated that open-weights models, when optimized for inference efficiency, can match proprietary systems such as Gemini 3 Pro.
II. Escaping Data Scarcity
For decades, the central bottleneck in automated theorem proving (ATP) was data scarcity. Unlike natural language, where the internet provides petabytes of text, the corpus of formalized mathematics is infinitesimal. In 2025, researchers broke this bottleneck through Synthetic Data Bootstrapping.
The Bootstrap Mechanism
The Goedel-Prover represents the most complete instantiation of this idea. Developed by Lin et al., Goedel-Prover utilizes an iterative learning from experience pipeline that allows the model to lift itself up by its own verified successes.
The architecture operates on a cycle of exploration and consolidation. First, the model attempts to generate proofs for auto-formalized statements. These traces are then subjected to a verification filter where the Lean kernel serves as an absolute oracle; unlike standard training where ground truth is ambiguous human text, here, if the code compiles, it is true. Crucially, the system then initiates bootstrapping. Successful proofs—specifically those the previous iteration failed to solve—are harvested to represent the frontier of the model’s capability and added back into the training set.
This cycle creates a positive feedback loop. As the system proves more theorems, it generates more high-quality training data, which in turn enables it to solve harder problems. On the MiniF2F benchmark, a standard test suite for formal reasoning, Goedel-ProverV2 achieved a success rate exceeding 88%, shattering the ceilings hit by previous systems that relied solely on static datasets.
The implication is fundamental. Mathematical reasoning can be scaled through compute and verification, not only through human annotation.
Synthetic Autarky
R-Zero advanced the Synthetic Autarky thesis by demonstrating that reasoning performance can improve without curated task datasets or even human-annotated reasoning traces. It proposes a co-evolutionary loop between two roles instantiated from a base model. A Challenger agent generates tasks near the edge of the Solver’s capability, and a Solver learns by attempting to solve them.
The system uses consistency and majority voting as proxies for truth, creating a closed loop where the model invents its own curriculum. It achieved massive gains on reasoning benchmarks without seeing a single human-annotated chain-of-thought example, suggesting that mathematical reasoning is an emergent property of sufficient compute and adversarial pressure.
Internalizing the Critic
If inference-time scaling made reasoning more capable, verification loops made it more reliable. While Western labs focused on external verifiers using Lean, DeepSeekMath-V2 focused on self-verification. It uses a Verifier-Generator architecture where the model trains a specific internal critic to judge its own reasoning traces.
The system trains a proof generator using this internal verifier as a reward model. A key design choice is to incentivize the generator to identify and resolve issues in its own proofs before finalizing them. This approach allowed it to score 118/120 on the Putnam 2024. The important point is not the headline score but the demonstration that System 2 behavior can be trained into a model through verification-conditioned objectives, reducing reliance on expensive external checking loops.
Closing the Loop
As AI proofs became longer, readability became a bottleneck. Thousands of steps of generated tactics are opaque to human intuition. ProofOptimizer targets that gap by training a model specifically to simplify Lean proofs through expert iteration. Using Lean itself to verify that simplifications preserve correctness, it reduced proof lengths by 87 percent on MiniF2F. This transformed spaghetti code into elegant arguments that human mathematicians can actually read and trust, ensuring that the industrialization of proof remains accessible to its architects.
III. Agents Architecture & Decomposition
Synthetic data alone is not sufficient. Even with verification, many mathematical problems remain intractable if treated as single-shot generation tasks. The next advance of 2025 addressed this limitation by shifting from monolithic provers to agentic systems that explicitly decompose problems and manage failure.
Recursive Decomposition
Hilbert formalized the strategy of Recursive Decomposition. The central insight is that many problems are too hard for a prover to solve directly but become trivial if broken into the right sub-problems. Hilbert orchestrates four distinct modules: a general-purpose Reasoner for informal planning, a specialized Prover for generating Lean tactics, a Verifier (Kimina Lean Server) for checking correctness, and a Retriever for finding theorems in Mathlib.
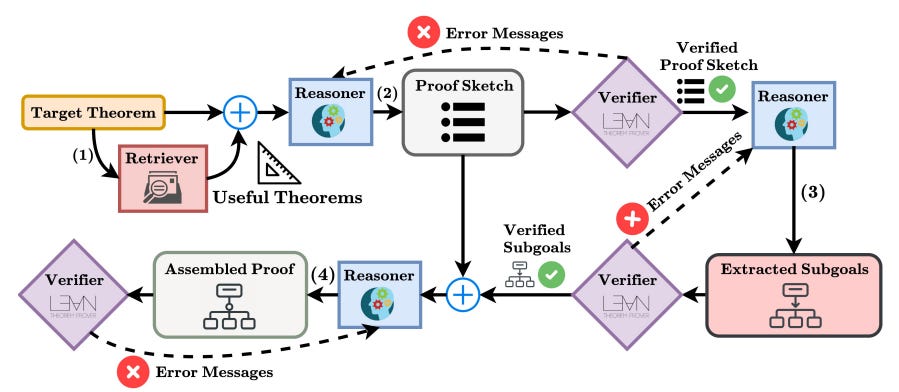
When the formal prover fails, Hilbert does not simply retry. It triggers a fallback mechanism where the Reasoner decomposes the goal into sub-goals or attempts a shallow solve, writing the proof in natural language first and then auto-formalizing the individual steps. This recursive structure allows Hilbert to navigate complex proof trees that would trap linear provers. It achieved a staggering 99.2% on miniF2F, and 70% on PutnamBench (50.4%).
Agentic Proof Construction
Released in December 2025, Seed-Prover 1.5 (ByteDance) rendered previous academic benchmarks obsolete by solving 11/12 problems on the Putnam 2025 exam. Crucially, this performance did not come from a stronger base model, but from a superior agentic architecture that prioritize structure and verification.
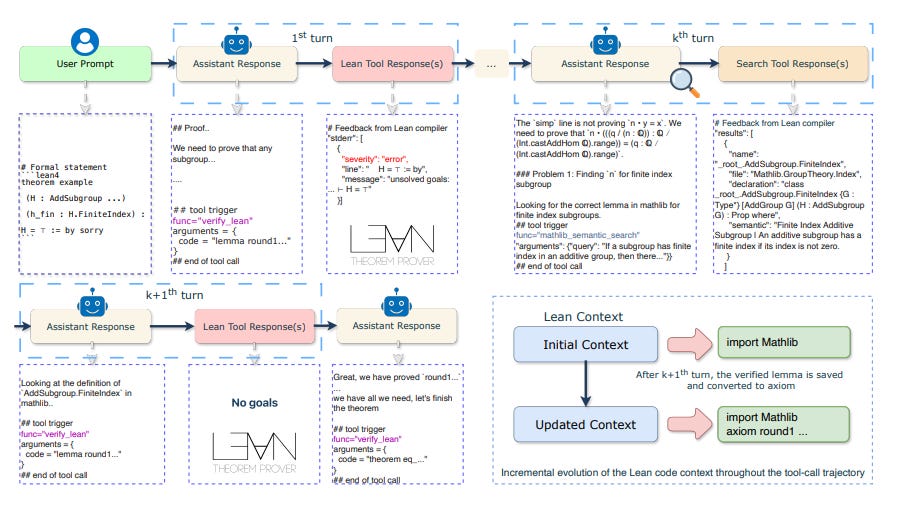
The system utilizes a Sketch Model to generate a high-level natural language strategy before writing formal code. Instead of writing a long proof in one pass, it employs Lemma-Style Interaction , proposing intermediate lemmas and verifying each with the Lean kernel before proceeding. By committing only to locally verified statements, the system avoids the cascading failures that plague single-shot proof generation.
The Graph Search Conductor
Harmonic’s Aristotle industrialized the topology of proof. While previous systems treated a proof as a branching tree of independent attempts, Aristotle treats it as a directed graph of reusable states. It achieved gold-medal-equivalent performance on the 2025 IMO by integrating three distinct architectural pillars.
Through Monte Carlo Graph Search, it identifies when distinct tactic sequences arrive at the identical mathematical state and merges them, collapsing the search space into a hypergraph. This effectively deduplicates the search for truth, preventing the model from squandering its inference budget on sub-problems it has already solved.
The system transforms the Poet vs. Compiler friction into a productive engine through a bidirectional Conductor Loop. Unlike earlier architectures that separate sketching from proving, Aristotle automates the negotiation between them: it fractures informal proofs into granular lemmas and attempts to formalize them. When the Lean kernel rejects a lemma, the system uses the compiler’s error messages to fundamentally revise the informal strategy, retaining the lemmas that survived and regenerating only those that failed.
Simultaneously, it employs Test-Time Training to retrain its policy on its own search traces during the exam, allowing the model to adapt its internal representations to the specific definitions and "APIs" of the theorem at hand.
IV. Back to Foundation: The Physics of Reasoning
The breakthroughs of 2025 were not only empirical. They were accompanied by a parallel shift in theoretical understanding that clarified why transformer-based systems can reason at all. We need to fundamentally understand the building block of LLM, the transformer.
Two papers published this year pushed back on the lingering metaphor and suggested that the recent success of reasoning models is not an accident of scale. It is a consequence of structure.
The Bayesian Geometry of Attention
The Bayesian Geometry of Transformer Attention turns that qualitative debate into a quantitative test. By placing transformers in Bayesian wind tunnels where the analytic posterior is known in closed form and memorization is provably impossible, researchers demonstrated that these networks are not merely matching patterns. They are implementing precise Bayesian updates.
The study revealed that the residual streams of the network function as a belief substrate. Information accumulates in these streams like evidence in the mind of a juror while the attention mechanism acts as a retrieval system that pulls relevant memories to update that belief. Most critically the authors discovered a low-dimensional value manifold parameterized by entropy. This means the model does not just encode a conclusion. It physically encodes its own uncertainty.
Transformers Know More Than They Can Tell
How do small transformer models learn complex arithmetic procedures under constrained data? In Transformers know more than they can tell, researchers utilized the Collatz iteration to expose the control structures hidden within the weights. The findings challenged the view of the model as a mere pattern matcher. The system did not memorize outputs. Instead, it acquired the underlying procedure sequentially and mastered the algorithm one loop at a time, with accuracy increasing in discrete steps as the model learned to recognize specific binary suffixes in the input
Rather than memorizing outputs, the models learn the underlying procedure one loop at a time. Competence increases in discrete jumps that track control-flow depth, consistent with the idea that models are acquiring algorithmic structure, not only statistical correlations.
The failure cases are especially diagnostic. When the model failed it almost never hallucinated random numbers. In over 90% of failures, the arithmetic calculation within each step was correct, but the model mispredicted the number of iterations required. Crucially, it defaulted to the longest loop lengths it had already mastered rather than the one required by the specific input. This implies a functional partition between calculation and control flow. The transformer distinguishes the execution of a step from the architecture of the loop. It suggests that even without explicit recursive code, the system organizes its internal representations to reflect the topology of a program.
The Industrial Complex
By late 2025, the cumulative breakthroughs in reasoning, verification, and self-generated data had begun to spill out of academic benchmarks and into genuine discovery workflows. Systems that once merely proved known theorems or benchmarks are now contributing to novel mathematical constructions, algorithmic advances, and scientific exploration.
These developments did not emerge by accident. They came from the intersection of long-term research, institutional capital, and industrial-scale compute that together reshaped the incentives and capabilities of AI systems.
Harmonic: The Verification Factory
Harmonic Math represents the capitalization of this shift. Following a Series C round led by Ribbit Capital, the company achieved a valuation of $1.45 billion on the thesis of Mathematical Superintelligence (MSI). Their ambition is to construct an Operating System for Truth, a platform that replaces the probabilistic approximations of current models with the provable certainties required by high-stakes industries such as finance and aerospace where hallucination is a liability.
Harmonic has characterized this new operational paradigm as Vibe Proving. The term captures the synthesis of two previously opposing modes: the stochastic, intuitive vibes of large language models are used not to generate final answers, but to guide the strict, mechanical rigor of formal verification.
The autonomous formalization of the Erdős Problems served as the vindication of this thesis. By converting natural language conjectures into formal code and verifying the logic against the Lean kernel, the system demonstrated that mathematical intuition could be tethered to the ironclad guarantees of machine proof, closing the discovery loop without human intervention.
Researchers can now use systems like Aristotle to generate formally verified proofs and explore mathematical constructions that would have been onerous for humans alone. This integration of formal verification and model reasoning exemplifies how reasoning systems are entering scientific workflows.
Math Inc: The Translation Utility
Math Inc. spun out of Morph Labs to address a different kind of bottleneck: the translation problem. Szegedy’s central thesis is that the limiting factor for artificial mathematical intelligence is not the capacity for reasoning but the scarcity of formal data. The logic of the machine is willing, but the corpus is weak.
In September their agent Gauss demonstrated the potential of infrastructure-scale formalization by tackling the Strong Prime Number Theorem. This project, championed by luminaries like Terence Tao and Alex Kontorovich, had languished for eighteen months, stalled by the notorious difficulty of formalizing complex analysis and contour integration within the rigid syntax of a proof assistant.
Guided by high-level blueprints from domain experts such as Jared Duker Lichtman, Gauss broke the deadlock. In just three weeks, it generated approximately 25,000 lines of verified Lean code, effectively treating formalization not as an artisanal craft but as a high-throughput utility. The result validated the Conductor model, proving that once a human provides the semantic scaffolding, an AI can handle the granular implementation with superhuman endurance.
Axiom: The Conjecture Engine
Another emerging institution in this space is Axiom Math, a startup that raised a substantial seed round in 2025. Founded with a focus on intelligence-constrained domains, the lab serves as a counterweight to the prevailing dogma of scale, focusing on intelligence-constrained domains where data is scarce but the underlying mathematical laws are immutable.
Hong’s founding thesis is that the standard large language model functions effectively as a competent secretary: excellent at retrieving existing knowledge, but fundamentally incapable of generating new insights. To bridge this gap, Axiom targets the creative spark of conjecturing. While other systems focus on verifying known statements, Axiom targets the discovery of new mathematical objects.
In 2025, Francois Charton led the lab's assault on one of the most stubborn strongholds in applied mathematics: Global Lyapunov Functions. For 130 years, constructing these functions which certify the stability of dynamical systems remained a dark art, a heuristic practice dependent on human intuition rather than algorithmic rigor. Axiom trained symbolic transformers to invert the problem.Rather than asking a model to find a function for a specific system, they trained it to learn the grammar of stability itself. The result was not merely a proof but a discovery. The model generated valid Lyapunov functions for non-polynomial systems that had successfully resisted human analysis, shifting the role of AI from checking homework to engineering reality.
DeepMind: Discovery at Scale
While Axiom targets the structure of dynamical systems, DeepMind’s AlphaEvolve targets the structure of algorithms themselves. Unveiled in May 2025, it departs from the rigid verification loops of the formal provers. Instead, it combines language generation with evolutionary search. The system operates on a Darwinian cycle: generating variations of code, evaluating them against automated metrics, and recombining the fittest survivors for further iteration.

This cycle produces a machine-driven exploration of algorithmic search spaces that extends beyond benchmarks into open problem solving. When applied to combinatorial challenges like the kissing number problem, the system did not merely verify known truths but improved them, generalizing results to formulae that hold for all input values rather than merely finite samples. The active collaboration with mathematicians such as Terence Tao and Javier Gómez-Serrano suggests a structural shift: these systems are no longer just checking proofs. They are generating the new constructions and algorithmic insights that require proving, effectively expanding the space of what is computable and discoverable with automation.
OpenMath: The Infrastructure of Truth
The transition to formal reasoning requires a new economic substrate. The OpenMath initiative, launched in October 2025 on the Shentuchain, creates a decentralized layer for this exchange. Developed in conjunction with CertiK, the protocol operates not merely as a tool but as an institutional record, addressing the fundamental deficits in the new economy of knowledge.
The first deficit is the bottleneck of verification. As AI systems generate proofs at industrial scale, the traditional peer review process, which is slow and prone to error, becomes untenable. OpenMath replaces this with a decentralized network of nodes running Lean and Rocq kernels, effectively commoditizing the act of checking truth.
The second deficit is the ambiguity of authorship. In a world where a human provides a conjecture, an agent sketches the proof, and a cluster verifies it, ownership becomes opaque. OpenMath solves this through an immutable ledger of attribution. It establishes a market for human-in-the-loop verification where researchers are incentivized to formalize the frontier of knowledge (the conjecture) and agents are rewarded for closing the loop (the proof). This infrastructure reinforces the central thesis of 2025: reasoning at scale becomes practical only when formal verification is connected to a shared, automated representation of knowledge.
The Scientific Singularity
The progression from Hilbert’s recursive decomposition to Aristotle’s agentic intuition represents something more profound than a software update. It marks a phase transition in the history of cognition. For three thousand years, mathematical truth was a handicraft, a bespoke product dependent on the biological limitations of the human neocortex and the sociological bottlenecks of peer review.
That era is over. The Symbolist tribe, who sought truth in rigid rules, and the Connectionist tribe, who found utility in statistical messiness, have finally merged. We have synthesized the machine that dreams with the machine that checks. The vibe of the neural network provides the intuition, and the rigor of the formal kernel provides the guarantee.
The result is a new industrial ecosystem, stratified not by prestige but by function. At the base lies the generalist behemoths pushing the boundaries of inference compute. On their shoulders stands the vertical specialists building the operating systems for verified truth. Binding them is the decentralized protocols, creating the incentive structures for this new knowledge economy.
We are likely only moments away from the first AI solving a Millennium Prize problem. But the specific trophy is irrelevant. What matters is the structural shift: we have successfully industrialized the production of certainty. The bottleneck to knowledge is no longer the scarcity of genius, but the cost of electricity.
The machinery is built.
Now, we just need to let it run.
Just found your post on Reddit. Interesting article, mate. Will follow your work.